Database System: Logging and Recovery
This note documents the mechanisms of logging and recovery.
- Logging: As transactions normally proceed, some records are made so that in case of a crash, these records can be used for recovery.
- Recovery: If a transaction crashes/fails, after the system restarts, the database needs to perform recovery operations.
Firstly, we need to be clear about what causes the database to need to recover, in other words, what we’ve been talking about - what does failure actually mean? We can only recover the first two:
- Transaction Failure
- Logical error (transaction conflict)
- Internal state error (e.g., must abort a transaction if there’s a deadlock)
- System Failure
- Software Failure (like a division by zero operation)
- Hardware Failure (power failure; when we discuss this, we are assuming that the data on the disk will not be damaged)
- Storage Media Failure
Next, let’s talk about logging, introducing from both why and how perspectives.
1. Why there are multiple logging mechanisms
We first need understand the operation mechanism between Schedule, Buffer Pool, and Disk. Let’s illustrate the process with an example:
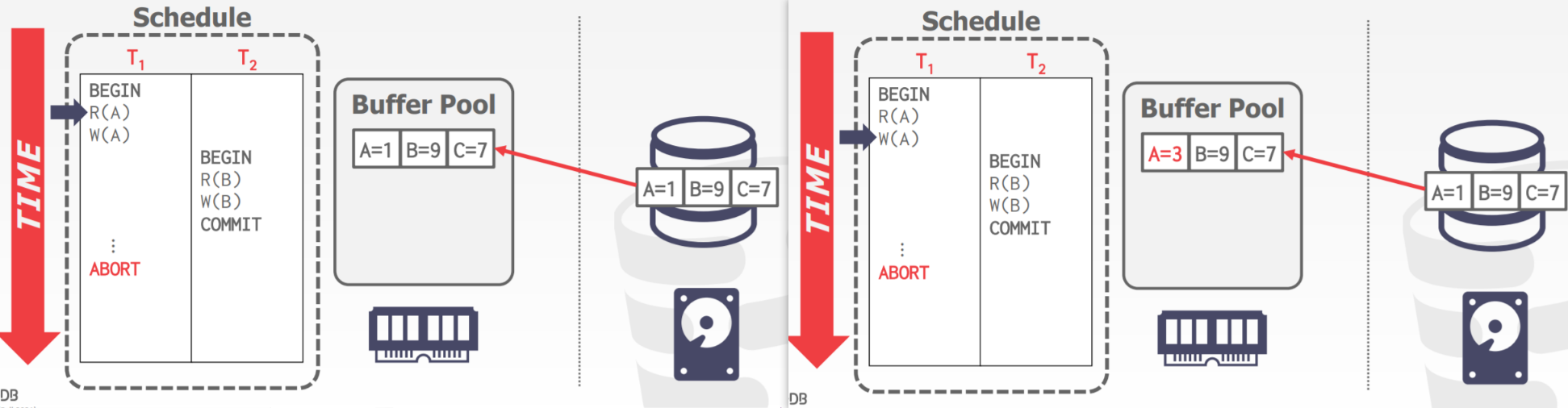
We start with reading data from the left diagram. The Schedule is controlled by the Execution Engine. Now we want to read A, so the Execution Engine sends a request for A to the Buffer Pool. The Buffer Pool checks whether the Page where A is located is in the Pool. If it is already there, it gives a Pointer to the Execution Engine and ensures that the Page containing A will always be in the Pool afterward. If it is not, it finds the Page where A is located from the Disk, moves the entire Page into the Pool, and then performs the above operations.
Then look at writing data in the right diagram. The Execution Engine, directed by the dispatched Pointer, can perform write operations on A. Write operations occur in the Buffer Pool in memory. Before the transaction commits, the modified data will not be written into the Disk (this statement may not be rigorous because in the case of Steal Policy, the data modified by the transaction that has not initiated commit may be accidentally written back to Disk by another transaction that has initiated commit). We call the Page that has been modified but not yet written back to Disk a Dirty Page.
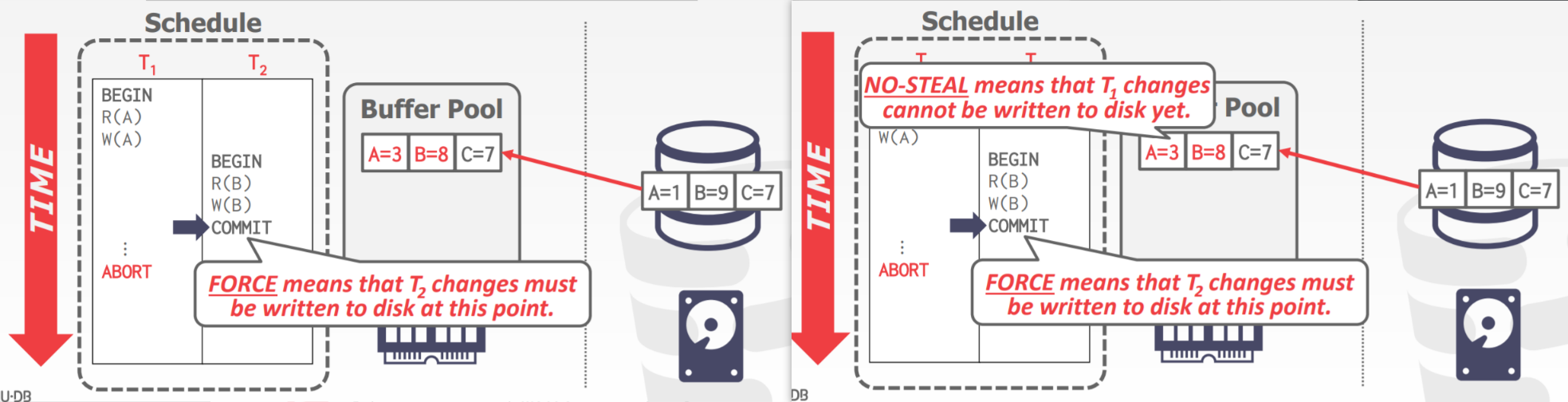
Next, look at the COMMIT operation. Here, I will explain the connection between this COMMIT and the Log mechanism.
When a transaction initiates a COMMIT, what exactly happens? I think we need to decompose COMMIT into two parts: one is the action of the transaction initiating a COMMIT, and the other is the action of the Log Manager writing this COMMIT log into the Disk. But what is the purpose of COMMIT? It’s to write data back to Disk. Here, we talk about three log methods, which are actually about when to write the COMMIT from the Log Manager into the Disk after the transaction initiates a COMMIT request, because only the data in the Disk is stable and safe, and the Log is also on Disk. This “when” refers to the point in time when the data is written back to Disk. If the COMMIT Log is written after the data is written back to Disk, we use the undo log; if the COMMIT Log is written before the data is written back to Disk, we use the redo log. The specific differences will be mentioned later.
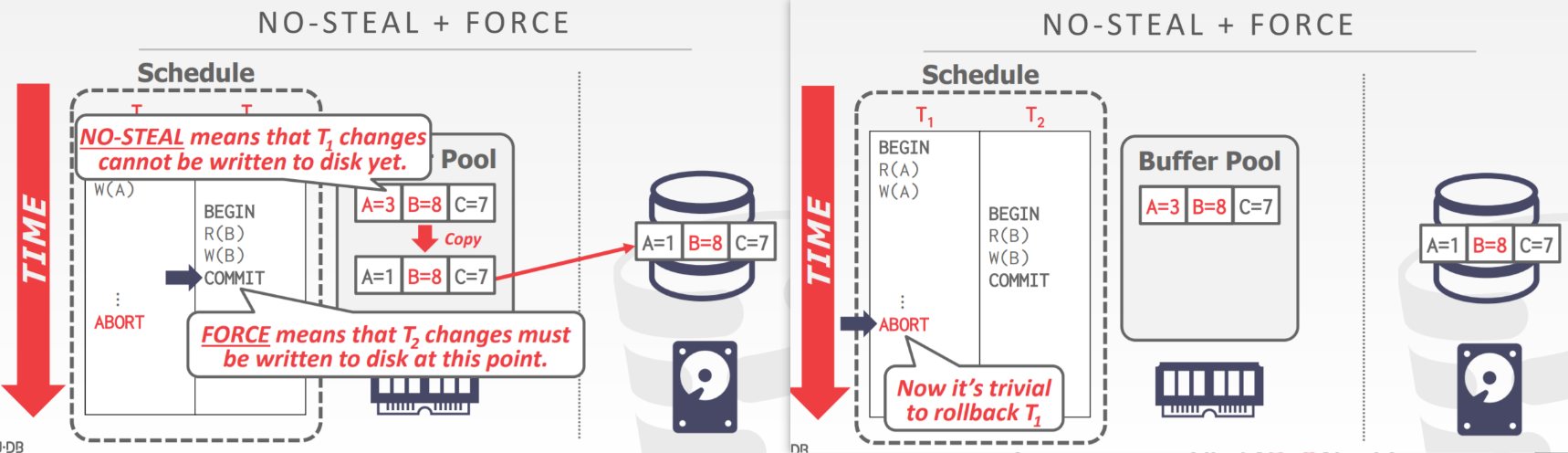
There are also two important concepts to talk about: Force and Steal policy.
If we adopt the Force Policy, it means that the data from this transaction must be written back to Disk at this time (forced to be written to disk). However, we know that the Buffer Pool operates with Pages, so what about the modified A in the figure above? The transaction it is part of has not initiated a COMMIT yet. This involves whether we allow Steal Page. If we allow the A that has not yet COMMITted to be written back to Disk along with it, then this is Steal Policy; if we do not allow A to be written back to Disk, then this is a Non-Steal Policy.
The above diagram displays the NO-STEAL + FORCE strategy. What are the benefits of this policy? Firstly, for all aborted transactions, we don’t need to perform undo operations, because the no-steal policy ensures that it will not be affected by other transactions, which means it will not be written back to Disk along with them. Secondly, for all committed transactions, we don’t need to perform redo operations because the force policy guarantees that it writes the data back to Disk when initiating a COMMIT request (here we assume that there will be no faults during the process of writing back to Disk).
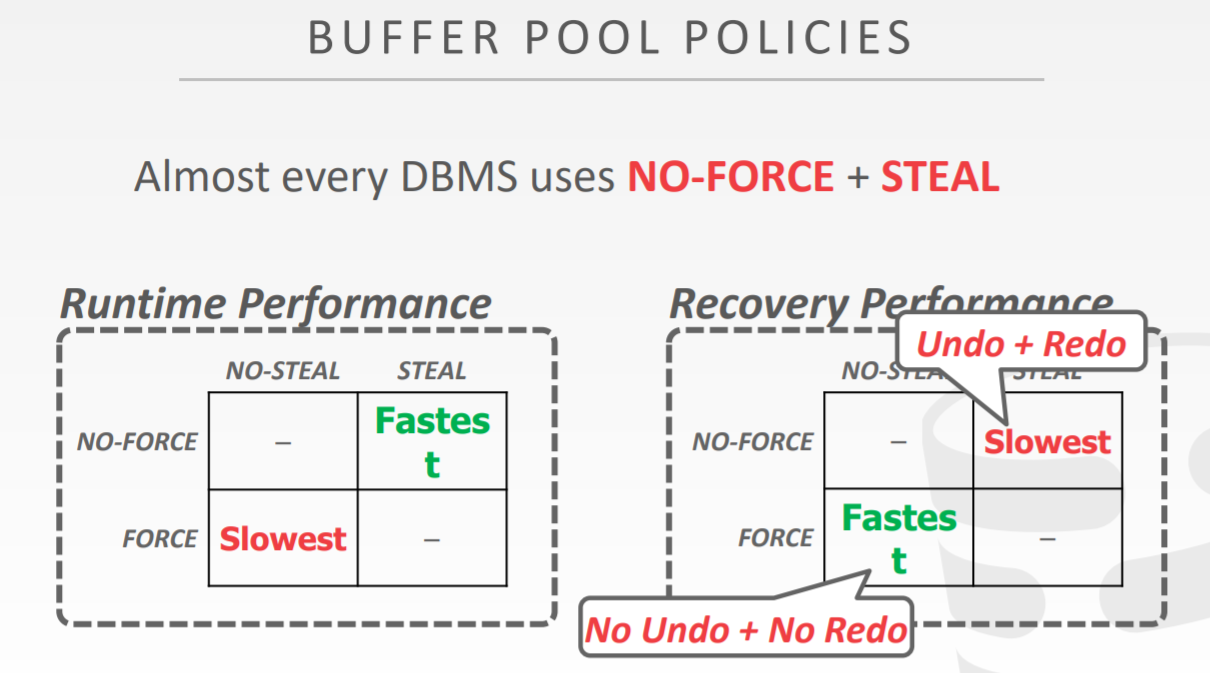
Why do we still have undo logs and redo logs since we can implement NO-STEAL + FORCE to avoid undo and redo… The reason is that the performance of NO-STEAL + FORCE is too low, it will cause many small disk IOs, leading to decreased performance. Usually, when we implement Buffer Pool, we use a NO-FORCE + STEAL policy. NO-FORCE means that committed items might not have been successfully written back, thus we need redo (to ensure Durability); STEAL means that uncommitted items might have been written back, thus we need undo (to maintain Atomicity). Therefore, we need a series of logging mechanisms.
In general, Logging is for making records, and making records is in case we need to Recovery. Based on what has been discussed above, we can conclude the following table about when what kind of log is needed:
| No Steal | Steal | |
|---|---|---|
| No Force | redo | redo + undo |
| Force | —— | undo |
2. How Logging and Recovery Work
2.1 Undo log
The Undo log is used to ensure Atomicity - the property of a transaction that guarantees that all operations in a transaction are executed or none are.
The logging process for the Undo log is as follows:
- A transaction (txn) starts, recording START T.
- The txn writes (X), and records (T, X, v) - where X is the modified object, and v is the old value.
- The txn writes committed updates to disk.
- The txn records COMMIT T (or ABORT T).
The recovery process using the Undo log is as follows:
- Scan the log from newest to oldest, finding all txns that have STARTed but have not yet COMMITted.
- For all txns that have not COMMITted, roll back to the state before START, using the Undo log.
Recall why we need undo? The data of txns that haven’t COMMITted might have been written to Disk because of STEAL POLICY.
Therefore, during recovery, we need to find all txns in the log that don’t have a COMMIT record, and undo them, which means rolling back to the state before START.
2.2 Redo log
The Redo log is used to ensure Durability - the property of a transaction that guarantees that the results of committed transactions survive permanently.
The logging process for the Redo log is as follows:
- A txn starts, recording START T.
- The txn writes (X), and records (T, X, v) - where X is the modified object, and v is the new value.
- The txn records COMMIT T (or ABORT T).
- The txn writes committed updates to disk.
The recovery process using the Redo log is as follows:
- Scan the log from oldest to newest, finding all txns that have COMMITted.
- For all COMMITted txns, redo the txn using the Redo log.
Why do we need redo? The txns that have already COMMITted might not have been successfully written to Disk because of the NO-FORCE POLICY.
Therefore, during recovery, we need to redo all the txns that have already COMMITted to make sure they’ve truly been written to Disk. For those txns that have not COMMITted, we handle them as aborts, ignoring them and not performing any operations.
2.3 Redo/Undo log
The Redo/Undo log is a combination of the Redo and Undo logs that ensures both Atomicity and Durability.
The logging process for the Redo/Undo log is as follows:
- A transaction (txn) starts, recording START T.
- The txn writes (X), and records (T, X, v, w) - where X is the modified object, v is the old value, and w is the new value.
- The txn records COMMIT T (or ABORT T) or the txn writes committed updates to disk.
The recovery process using the Redo/Undo log is as follows:
- Scan the log from newest to oldest to find all txns that haven’t COMMITted, and from oldest to newest to find all COMMITted txns.
- Undo the txns that haven’t COMMITted, and redo the txns that have COMMITted.
In the third step of the Redo/Undo log process, either order is fine. During recovery, the UNDO LOG is used to undo the txns that have not COMMITted, and the REDO LOG is used to redo the txns that have COMMITted.
3. Checkpoint
To speed up recovery and better utilize space, we introduce the concept of a checkpoint. The core idea of a checkpoint mechanism is to periodically save the state of the system. In the event of a system failure, recovery can begin from the most recent checkpoint rather than starting from scratch.
3.1 Simple Checkpoint
In the simple checkpoint mechanism, the system periodically generates a checkpoint, pausing all transaction execution, writing all modified but yet to be written to disk data pages (also called dirty pages), and transaction logs to disk, then resuming transaction execution.
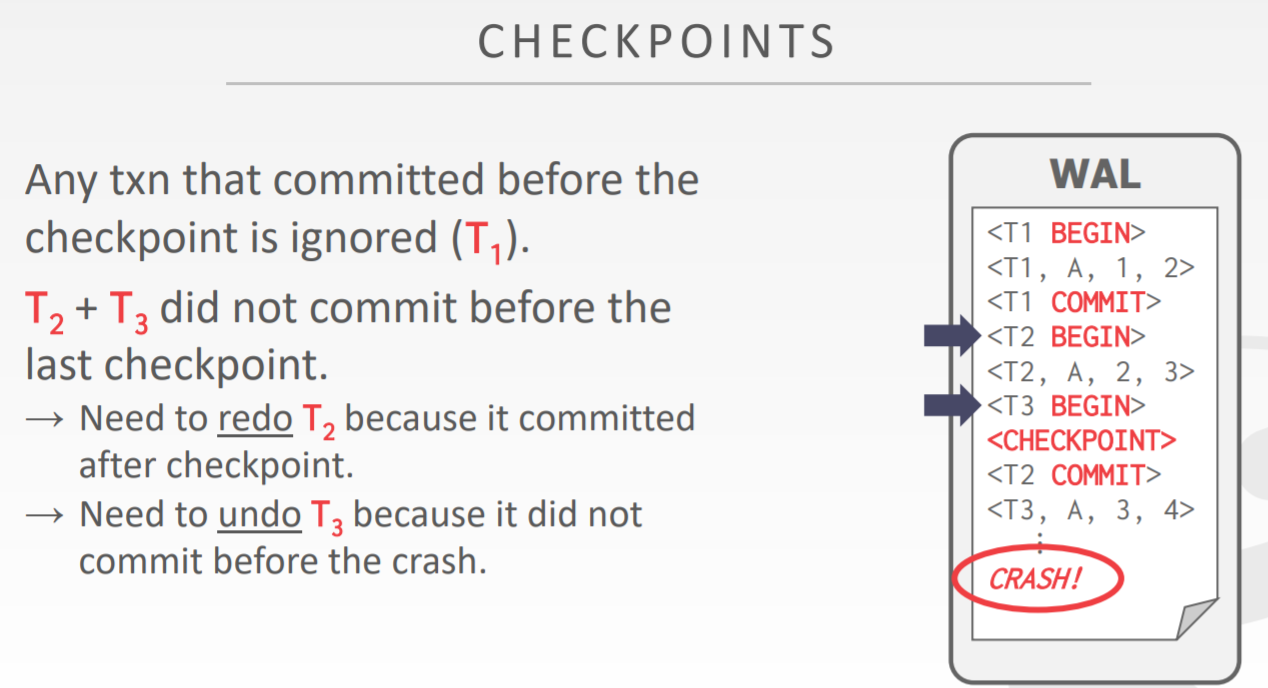
During system recovery, we can start from the most recent checkpoint and redo and undo all transaction logs after this. The drawback of this method is that it requires pausing all transaction execution when generating a checkpoint, which can degrade system performance if there are many transactions or a large amount of data.
3.2 ARIES Checkpoint for undo/redo log
ARIES (Algorithm for Recovery and Isolation Exploiting Semantics) is a widely used recovery algorithm that provides an efficient checkpoint mechanism. Unlike the simple checkpoint mechanism, ARIES doesn’t need to pause all transaction execution when generating a checkpoint. It just needs to record the information of currently executing transactions and all dirty pages in the system.
The ARIES checkpoint mechanism has three important steps:
BEGIN CHECKPOINT: At the beginning of generating a checkpoint, the system generates a BEGIN CHECKPOINT record and writes it to the log. This record contains information about all transactions currently being executed.
Save dirty page information: The system records the information of all current dirty pages and writes this information to disk. This information can be used to determine which pages may need redo operations during system recovery.
END CHECKPOINT: The system generates an END CHECKPOINT record and writes it to the log. This record contains information about all transactions that started after BEGIN CHECKPOINT and ended before END CHECKPOINT, as well as all dirty pages in the system at the time of END CHECKPOINT.
During system recovery, ARIES first starts from the most recent checkpoint, then analyzes all transaction logs after this, deciding which transactions need redo and undo operations.
Compared with the simple checkpoint mechanism, the ARIES checkpoint mechanism can generate checkpoints without pausing transaction execution, thus improving system performance.